NullSwap: Proactive Identity Cloaking Against Deepfake Face Swapping (2025)
Bài này không có code
Dataset
CelebA-HQ
Labeled Faces in the Wild (LFW)
Ý tưởng
Chủ động chèn các nhiễu loạn (perturbations) không thể nhìn thấy vào hình ảnh nguồn để làm mù các bộ trích xuất danh tính của các mô hình hoán đổi khuôn mặt
=> Điều này khiến cho các hình ảnh tổng hợp được tạo ra có danh tính không mong muốn, từ đó vô hiệu hóa Deepfake hoán đổi khuôn mặt
Mô hình đề xuất
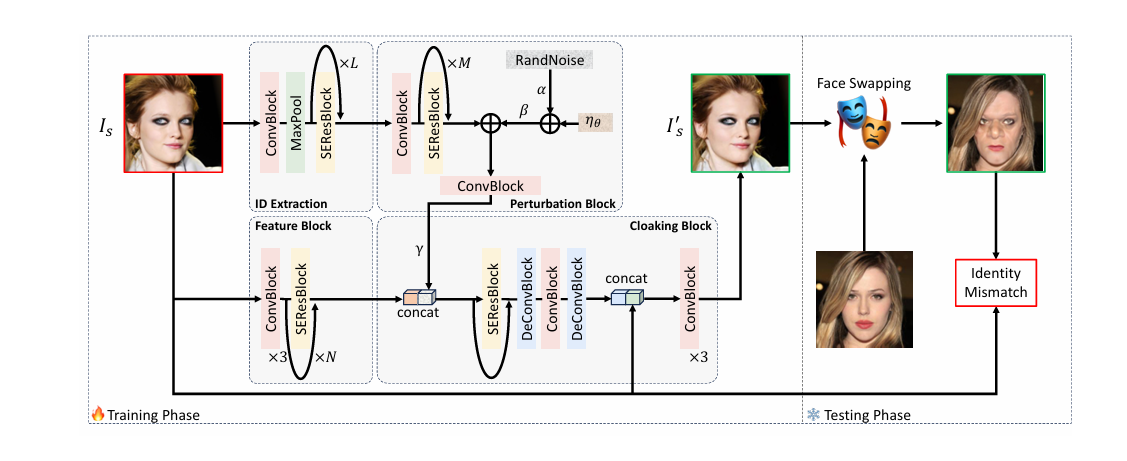
ID Extraction
Mục tiêu: Phân tích hình ảnh đầu vào Is để thu được các đặc trưng danh tính.
Ý nghĩa: Duy trì đặc trưng sâu và quan trọng của ảnh
Điểm mới: Duy trì các đặc trung danh tính ở dạng ma trận thay vì vector
Cấu trúc: 1 ConvBlock (CNN + BatchNorm + Relu) + 1 Max-pooling + L (L = 4)
SEResBlock (BottleResNet + SENet)
Perturbation Block
Mục tiêu: Tạo ra nhiễu loạn đucợ hướng dẫn bởi danh tính để che dấu danh tính
cuối cùng
Ý nghĩa: Tổng hợp đặc trưng phân cấp, bảo toàn các đặc trưng danh tính liên
quan nhất, triệt tiêu các đặc trung ít liên quan
Điểm mới: Qua nhiều lớp SEResBlock để tập trung vào các đặc trưng quan trọng
Cấu trúc:
1 ConvBlock + M (M = 3) SEResBlock (BottleResNet + SENet) (1)
RandNoise = β · (α · RandNoise + η) α , β, η là learnable parameters (2)
(1) với (2) kết nối với nhau qua khối ConvBlock
Feature Block
Mục tiêu: Trích xuất các đặc trưng hình ảnh ở mức độ nông từ Is
Ý nghĩa: Lấy đặc trung nông để không ảnh hưởng lớn đến các đặc trưng sâu,
hiệu quả hơn để bảo toàn danh tính
Cấu trúc: 3 ConvBlock + N (N = 5) SEResBlock
Cloaking Block
Mục tiêu: Kết hợp các đặc trưng hình ảnh với nhiễu loạn đã tạo ra để tái tạo
hình ảnh đầu vào Is thành I's với nhiễu loạn được nhúng một cách vô hình
Ý nghĩa: Hòa lẫn nhiễu để không dễ nhìn thấy
Cấu trúc:
- Gán 1 trọng số Y có thể học được từ khối nhiễu loạn
- Concat với đặc trưng từ khối nông
- Thực hiện tái tạo ở mức độ đặc trưng như theo hình
- Ảnh cuối cùng qua 3 ConvBlock
Hàm mất mát
Loss tổng: L total = λ id L id + λ MSE L MSE + λ LPIPS L LPIPS + λ D L D (với λ là các tham số biết
trước)
-
L id: Tổng trọng số của các mô hình nhận diện khuôn mặt
Với việc áp dụng thêm cơ chế Dynamic Loss Weighting - DLW: Để đảm bảo tính tổng quát khi đối mặt với các thuật toán hoán đổi khuôn mặt sử dụng các bộ trích xuất danh tính khác nhau, NullSwap sử dụng nhiều công cụ nhận diện khuôn mặt. DLW được thiết kế để cân bằng thích nghi các mục tiêu mất mát từ các thuật toán nhận diện khuôn mặt khác nhau trong quá trình huấn luyện -
L MSE: Đo lường độ tương đồng pixel giữa ảnh input và output
||I s - I' s || 2 -
L LPIPS: Đo lường độ tương đồng giữa các đăc trưng sâu thông qua pretrained AlexNet tại layer l
-
L D: Đo lường độ tương đồng giữa thật và giả qua cơ chế phân loại nhị phân
Ảnh thực nghiệm


Ưu Điểm
- Hiệu quả cao trong việc che giấu danh tính nguồn.
- Chất lượng hình ảnh được bảo toàn xuất sắc.
- Hoạt động trong black-box hoàn toàn (không cần output)
- Tính tổng quát vượt trội nhờ cơ chế DLM.
Nhược Điểm
Nhược điểm không đề cập nhưng có thể là việc cân bằng giữa hiệu suất và độ tổng quát. Bài báo cũng nói rằng việc dựa vào input không cần output sẽ là xu thế trong tương lai